Towards a more efficient systematic review: can AI replace double human screening?
5 min read
AI
The article shows that, under human supervision, AI—such as NOÉ’s—can replace a second reviewer while ensuring speed, reliability, and scientific rigor.

Introduction
Traditionally, two reviewers are involved to limit bias. However, with the emergence of machine learning (ML)-based tools, this approach has been challenged. Are these tools reliable enough to replace the second reviewer?
What the PRISMA 2020 Explanation and Elaboration: Updated Guidance and Exemplars for Reporting Systematic Reviews says
In the PRISMA 2020 guidance¹, it is clearly stated that automation tools may be used:
“whether they were used in lieu of or in addition to human reviewers”
In concrete terms, this means that a single human reviewer can be assisted by an automation tool, particularly for excluding clearly irrelevant studies or for prioritizing screening.
Are there conditions under which AI can replace a second reviewer?
According to the PRISMA 2020 guidance, this requires:
Clearly declaring the use of the tool, its function (screening, exclusion, prioritization), and its role in the decision-making chain.
Demonstrating that the tool has been validated and that an acceptable performance threshold has been reached (each solution defines its own threshold; at NOÉ, this threshold is set above 95%).
Providing for human review of ambiguous or borderline cases.
Performance of machine learning tools: what do studies say?
Several tools such as AbstrackR or Rayyan have already shown that AI can accelerate systematic review screening with acceptable quality².
However, until recently, few studies directly compared these approaches with double human screening.
A study published in March 2025 in Research Synthesis Methods, entitled “Machine learning for identifying randomised controlled trials when conducting systematic reviews: Development and evaluation of its impact on practice”³, changes the landscape. It provides a clear comparison of two AI integration strategies and allows a precise assessment of their effectiveness compared with traditional methods.
Strategy 1 – Parallel screening: AI as a full reviewer
In this strategy, AI performs the full screening of all abstracts, exactly as a human reviewer would.
In parallel, a human reviewer independently reads and selects the same abstracts.
Each system (AI and human) delivers its own judgment for each abstract.
In the event of disagreement, arbitration is performed (by consensus or via a third opinion).
This therefore constitutes a complete double screening, with one reviewer replaced by AI.
Results:
Recall (proportion of relevant articles correctly included) > 99.8%
Significant time savings (~45%)
Very low risk of omission
Strategy 2 – Hierarchical screening: AI filters, humans review only what AI selects
In this model, AI alone first screens all abstracts and classifies documents into two categories: potentially relevant vs. probably not relevant.
Only abstracts deemed relevant by AI are then reviewed by a human reviewer.
All others are directly excluded, without human review.
This approach is even faster but relies heavily on confidence in the algorithm’s initial screening.
Results:
Very high time savings (~74%)
Slightly lower recall (97%): some marginally relevant studies may be lost, as they are never reviewed by a human.
Study conclusion: optimal human–AI collaboration

The study concludes that the best balance between selection quality and time efficiency is achieved with the parallel screening strategy.
This model preserves a high level of reliability (recall > 99.8%) while significantly reducing workload.
Conversely, hierarchical screening—although faster—may lead to the erroneous exclusion of certain relevant articles, which can undermine the robustness of a systematic review.
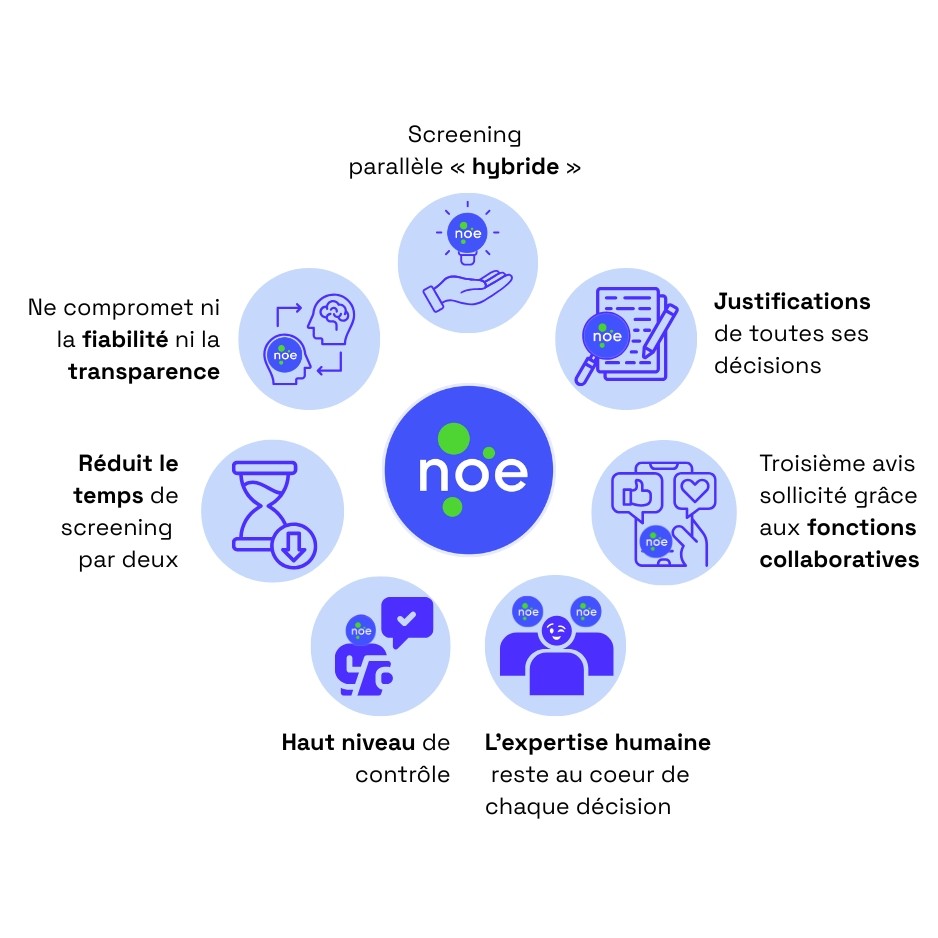
NOÉ: a supervised hybrid model inspired by hierarchical screening
NOÉ offers a hybrid parallel screening approach: the human reviewer and the AI independently review the same abstracts.
The AI explains all its inclusion and exclusion decisions. In the event of disagreement, arbitration is carried out by the expert, and a third opinion can also be requested thanks to the platform’s collaborative features.
Human expertise remains at the core of every decision. This approach makes it possible to maintain a high level of control while halving screening time, without compromising reliability or methodological transparency.
NOÉ therefore makes it possible to dispense with a second reviewer while complying with the requirements for transparency, traceability, and methodological rigor defined by PRISMA.
AI versus human error
Beyond efficiency gains, the contribution of AI is also reflected in the reduction of human error, even among experienced reviewers. Several studies demonstrate this, opening the way for a broader reflection on the reliability of manual screening.
Multiple studies have shown that screening errors are frequent, even among experienced human reviewers. According to Waffenschmidt et al. (2019)⁴, up to 13% of relevant studies may be incorrectly excluded during single-reviewer manual screening.
The use of an algorithm makes it possible to:
Reduce inter-individual variability (linked to subjectivity or fatigue),
Apply selection criteria consistently, thereby reducing the risk of erroneous exclusion.
This is also confirmed by Gates et al. (2019)⁵, who show that a well-trained AI can achieve performance superior to that of a single human reviewer, while reducing processing time by 30 to 50%.
From this perspective, using AI not only improves efficiency but also enhances methodological safety by limiting selection bias.
Towards professional adoption of AI in screening
NOÉ fully aligns with the methodological evolution of systematic reviews by offering a dedicated, already operational AI that complies with the transparency and validation standards defined by PRISMA 2020.
Far from being a simple concept, NOÉ is designed for concrete integration into professional practices, with:
Systematic human supervision,
Progressive learning of project-specific selection criteria, and
Full traceability of all decisions.
NOÉ provides a balanced and reliable solution, aligned with a new hybrid collaboration model between AI and humans.
Approaches such as parallel or supervised screening make it possible to combine speed, reliability, and traceability, provided that humans remain involved in the final validation.
In other words, double human screening is no longer always indispensable. The question is no longer whether AI can replace a second reviewer, but under which conditions it can do so without compromising scientific rigor.
Recent work on the subject and analysis of the latest recommendations have shown that a single human reviewer, assisted by AI, may be sufficient in many contexts, provided that the AI used complies with transparency standards and allows clear human oversight.
It can therefore be concluded that today, certain conditions are in place to adopt AI in the screening phase.
Bibliographic references
¹ Tricco, A. C., Lillie, E., Zarin, W., O’Brien, K. K., Colquhoun, H., Levac, D., … & Straus, S. E. (2021). PRISMA 2020 explanation and elaboration: updated guidance and exemplars for reporting systematic reviews. BMJ, 372, n160. https://doi.org/10.1136/bmj.n160
² Gates, A., Guitard, S., Pillay, J., Elliott, S. A., Dyson, M. P., Newton, A. S., & Hartling, L. (2019). Performance and usability of machine learning for screening in systematic reviews: a comparative evaluation of three tools. Systematic Reviews, 8(1), 278. https://doi.org/10.1186/s13643-019-1185-3
³ Qin, X., Yao, M., Luo, X., Liu, J., Ma, Y., Liu, Y., Li, H., Deng, K., Zou, K., Li, L., & Sun, X. (2025). Machine learning for identifying randomised controlled trials when conducting systematic reviews: Development and evaluation of its impact on practice. Research Synthesis Methods, 16(3), 350–363. https://doi.org/10.1007/rsm.2025.3
⁴ Waffenschmidt, S., et al. (2019). Single screening versus conventional double screening for study selection in systematic reviews: a methodological study. BMC Medical Research Methodology, 19, 132. https://doi.org/10.1186/s12874-019-0770-1
⁵ Gates, A., Guitard, S., Pillay, J., Elliott, S. A., Dyson, M. P., Newton, A. S., & Hartling, L. (2019). Performance and usability of machine learning for screening in systematic reviews: a comparative evaluation of Abstrackr and a novel tool using a randomized controlled trial dataset. Systematic Reviews, 8, 278. https://doi.org/10.1186/s13643-019-1185-3